针对基于 Diffusion 和 LLM 类别的 TTS 模型,NVIDIA Triton 和 TensorRT-LLM 方案能显著提升推理速度。在单张 NVIDIA Ada Lovelace GPU 上,F5-TTS 模型每秒可生成长达 25 秒的音频;Spark-TTS 在流式合成场景下,首包延迟可低至 200 余毫秒。
Text-to-Speech (TTS) 是智能语音技术的核心组成部分。随着大模型时代的到来,TTS 模型的参数量和计算量持续增长,如何高效利用 GPU 部署 TTS 模型,构建低延迟、高吞吐的生产级应用,已成为开发者日益关注的焦点。
本文将围绕两款 Github 社区流行的 TTS 模型——F5-TTS[1]和 Spark-TTS[2]——详细介绍运用NVIDIA Triton推理服务器和 TensorRT-LLM 框架实现高效部署的实践经验,包括部署方案的实现细节、具体使用方法及最终的推理效果等。开发者可根据不同的应用场景选择合适的方案,并可利用性能分析工具调整配置,以最大化利用 GPU 资源。
方案介绍
当前主流的 TTS 大模型大致可分为两类:非自回归扩散模型和自回归 LLM 模型。非自回归扩散模型因其解码速度快,易于实现高吞吐性能;而自回归 LLM 模型则以更佳的拟人效果和对流式合成的天然支持为特点。实践中,常有方案将两者结合,先使用自回归 LLM 生成语义 Token,再利用非自回归扩散模型生成音频细节。
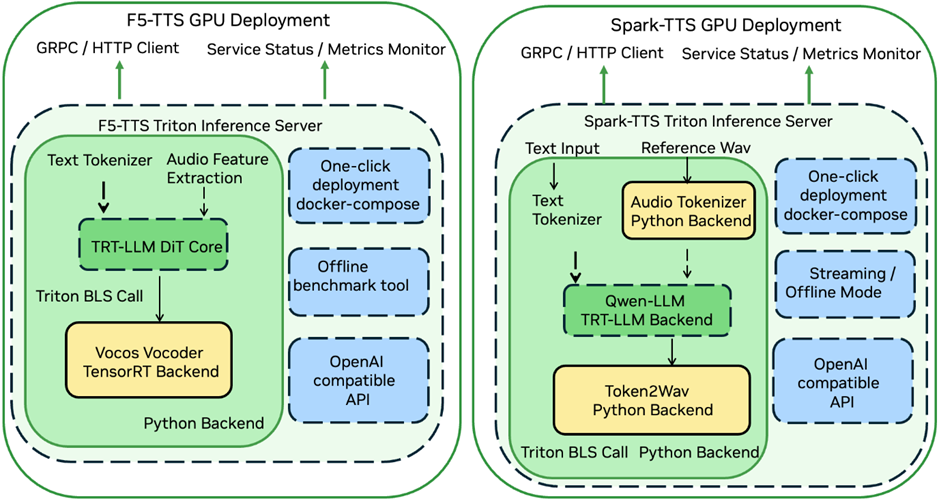
图1: TTS 部署方案结构
F5-TTS
F5-TTS 是一款非自回归扩散 TTS 模型,它基于 DiT (Diffusion Transformer) 和 Flow-matching 算法,移除了传统非自回归 TTS 模型中的 Duration 模块,使模型能直接学习文本到语音特征的对齐。
其推理加速方案利用NVIDIA TensorRT-LLM加速计算密集的 DiT 模块,并采用 NVIDIA TensorRT 优化 Vocos 声码器,最后通过 NVIDIA Triton 进行服务部署。
方案地址:
https://github.com/SWivid/F5-TTS/tree/main/src/f5_tts/runtime/triton_trtllm
Spark-TTS
Spark-TTS 是一款自回归 LLM TTS 模型,它采用经过扩词表预训练的 Qwen2.5-0.5B LLM 来预测 Speech Token,并基于 VAE Decoder 重构最终音频。
其部署方案通过 NVIDIA TensorRT-LLM 加速基于 LLM 的语义 Token 预测模块,并借助 NVIDIA Triton 串联其余组件,支持离线合成与流式推理两种模式。
方案地址:
https://github.com/SparkAudio/Spark-TTS/tree/main/runtime/triton_trtllm
方案性能
我们从WenetSpeech4TTS 测试集[3]中选取了 26 组 Prompt Audio 和 Target Text 音频文本对,在 Zero-shot 音色克隆任务上测试了模型的推理性能。测试细节如下:
F5-TTS
针对 F5-TTS,我们在 Offline 模式下(即直接在本地进行推理,不涉及服务部署和请求调度)测试了 TensorRT-LLM 推理方案的性能:
测试结果如下(Batch Size 固定为 1,因当前 F5-TTS 版本暂不支持 Batch 推理;Flow-matching 推理步数固定为 16):
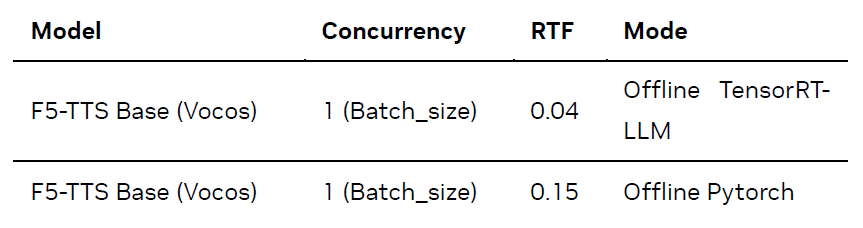
如上表所示,与原生 PyTorch 实现(默认启用 SDPA 加速)相比,NVIDIA TensorRT-LLM方案在 Ada Lovelace GPU 上实现了约 3.6 倍的加速,每秒可生成的音频时长从 7 秒提升至 25 秒。
Spark-TTS
对于 Spark-TTS,我们在 Client-Server 模式下(即客户端向服务器发送请求)测试了端到端推理服务的性能。测试结果如下(Offline 模式不统计首包延迟,Streaming 模式首包音频长度为 1 秒):
上表结果中,LLM 模块默认启用了 TensorRT-LLM 的inflightbatching 模式。为模拟多路并发场景,我们基于 Python asyncio 库实现了一个异步并发客户端。此部署方案在 Ada Lovelace GPU 上,每秒可生成约 15 秒音频,流式模式下的首包延迟低至 200 余毫秒。
快速上手
本节将指导您如何快速部署和测试 F5-TTS 与 Spark-TTS 模型。在此之前,建议您先克隆对应的代码仓库,并进入runtime/triton_trtllm目录操作。
F5-TTS
详细步骤请参考F5-TTS/src/f5_tts/runtime/triton_trtllm/README.md和run.sh脚本。
1. 最简部署 (Docker Compose):这是启动 F5-TTS 服务最快捷的方式。
# 根据您的模型选择,例如 F5TTS_Base MODEL=F5TTS_Base docker compose up
(注意:F5TTS_v1_Base的支持可能仍在开发中,请检查项目 README)
2. 手动部署与服务启动:如果您需要更细致地控制部署流程,可以使用run.sh脚本分阶段执行。
# 脚本参数:[model_name] # 例如,执行阶段0到4,使用 F5TTS_Base 模型 bashrun.sh04F5TTS_Base
这个命令会依次执行以下主要步骤:
Stage 0:下载 F5-TTS 模型文件。
Stage 1:转换模型权重为 TensorRT-LLM 格式并构建引擎。
Stage 2:导出 Vocos 声码器为 TensorRT 引擎。
Stage 3:构建 Triton 推理服务器所需的模型仓库。
Stage 4:启动 Triton 推理服务器。
3. 测试服务:服务启动后,您可以使用提供的客户端脚本进行测试。
gRPC 客户端 (数据集 Benchmark):
# 示例命令,对应 run.sh stage 5 # 具体参数(如 num_task, dataset)请根据需求调整 python3 client_grpc.py --num-tasks 1 --huggingface-dataset yuekai/seed_tts --split-name wenetspeech4tts --log-dir ./log_f5_grpc_bench
HTTP 客户端(单句测试):
# 示例命令,对应 run.sh stage6
# audio, reference_text, target_text 请替换为您的测试数据
python3 client_http.py--reference-audio ../../infer/examples/basic/basic_ref_en.wav
--reference-text "Some call me nature, others call me mother nature."
--target-text "I don't really care what you call me. I've been a silent spectator, watching species evolve, empires rise and fall. But always remember, I am mighty and enduring."
4. OfflineTensorRT-LLM基准测试:如果您希望直接测试 TensorRT-LLM 在 Offline 模式下的性能(不通过 Triton 服务),可以执行run.sh中的 Stage 7。
# 此命令对应 run.sh stage 7
# 环境变量如 F5_TTS_HF_DOWNLOAD_PATH, model, vocoder_trt_engine_path, F5_TTS_TRT_LLM_ENGINE_PATH
# 通常在 run.sh 脚本顶部定义,请确保它们已正确设置或替换为实际路径。
batch_size=1
model=F5TTS_Base# 示例模型名称
split_name=wenetspeech4tts
backend_type=trt
log_dir=./log_benchmark_batch_size_${batch_size}_${split_name}_${backend_type}
# 确保以下路径变量已设置,或直接替换
# F5_TTS_HF_DOWNLOAD_PATH=./F5-TTS (示例)
# F5_TTS_TRT_LLM_ENGINE_PATH=./f5_trt_llm_engine (示例)
# vocoder_trt_engine_path=vocos_vocoder.plan (示例)
rm-r$log_dir2>/dev/null
# ln -s ... # 符号链接通常在 run.sh 中处理,按需创建
torchrun --nproc_per_node=1
benchmark.py --output-dir$log_dir
--batch-size$batch_size
--enable-warmup
--split-name$split_name
--model-path$F5_TTS_HF_DOWNLOAD_PATH/$model/model_1200000.pt
--vocab-file$F5_TTS_HF_DOWNLOAD_PATH/$model/vocab.txt
--vocoder-trt-engine-path$vocoder_trt_engine_path
--backend-type$backend_type
--tllm-model-dir$F5_TTS_TRT_LLM_ENGINE_PATH||exit1
Spark-TTS
详细步骤请参考Spark-TTS/runtime/triton_trtllm/README.md和run.sh脚本。
1. 最简部署 (Docker Compose):
dockercompose up
2. 手动部署与服务启动:使用run.sh脚本进行分阶段部署。
#脚本参数:[service_type] #service_type 可为'streaming'或'offline',影响模型仓库配置 #例如,执行阶段0到3,部署为 offline 服务 bash run.sh 0 3 offline
此命令会执行:
Stage 0:下载 Spark-TTS 模型。
Stage 1:转换模型权重并构建 TensorRT 引擎。
Stage 2:根据指定的 service_type (streaming/offline) 创建 Triton 模型仓库。
Stage 3:启动 Triton 推理服务器。
3. 测试服务 (Client-Server 模式):服务启动后,可使用客户端脚本进行测试。
gRPC 客户端 (数据集 Benchmark):此命令对应run.sh中的 stage 4。
# 示例:测试 offline 模式,并发数为2
# bash run.sh 4 4 offline
# 其核心命令如下:
num_task=2
mode=offline# 或 streaming
python3 client_grpc.py
--server-addr localhost
--model-name spark_tts
--num-tasks$num_task
--mode$mode
--huggingface-dataset yuekai/seed_tts
--split-name wenetspeech4tts
--log-dir ./log_concurrent_tasks_${num_task}_${mode}
单句测试客户端: 此命令对应run.sh中的 stage 5。
Streaming 模式 (gRPC):
# bash run.sh55streaming # 其核心命令如下: python client_grpc.py --server-addr localhost --reference-audio ../../example/prompt_audio.wav --reference-text $prompt_audio_transcript --target-text $target_audio_text --model-name spark_tts --chunk-overlap-duration 0.1 --mode streaming
Offline 模式 (HTTP):
# bash run.sh 5 5 offline # 其核心命令如下: python client_http.py --reference-audio ../../example/prompt_audio.wav --reference-text$prompt_audio_transcript --target-text$target_audio_text --model-name spark_tts
兼容 OpenAI 格式的 API
许多开源对话项目 (如 OpenWebUI)[4]已支持 OpenAI 格式的 TTS API。为方便开发者集成,我们提供了兼容 OpenAI API 的服务,用法如下:
git clone https://github.com/yuekaizhang/Triton-OpenAI-Speech.git
cdTriton-OpenAI-Speech
docker compose up
curl$OPENAI_API_BASE/audio/speech
-H"Content-Type: application/json"
-d '{
"model":"spark_tts",
"input":$target_audio_text,
"voice":"leijun",
"response_format":"pcm"
}'|
sox-t raw-r16000-e signed-integer-b16-c1-output3_from_pcm.wav
总结
无论是 F5-TTS 或是 Spark-TTS,都可以看到 NVIDIA Triton 推理服务器和 TensorRT-LLM 框架可以大幅提升 TTS 模型的推理速度,也方便开发者进行模型部署。我们将持续增加对更多语音多模态模型的部署支持。
除了TTS,NVIDIA 技术团队也为多种社区流行的多模态模型开发了最佳实践,详细方案介绍以及教程,请参阅 mair-hub[5]项目。
近期我们还将举办一场和该主题相关的在线研讨会,欢迎大家报名参加,共同交流和探讨。
作者
张悦铠
张悦铠是 NVIDIA 解决方案架构师,硕士毕业于约翰霍普金斯大学,导师为 Shinji Watanabe 教授,主要研究方向为语音识别。NVIDIA 中文语音识别解决方案主要开发者,对基于 GPU 的语音识别服务部署及优化有丰富经验。